1. The Idea Behind Flooky – Your Own AI, On Your Terms
Large language model UIs are everywhere now: official dashboards, browser extensions, Slack bots, VS Code add-ons… But most of them have one thing in common: they’re tied to someone else’s platform, someone else’s UI, and someone else’s data decisions.
I wanted something different:
- A simple web app I control, running on my own server.
- A clean, focused chat UI without the noise of 20 extra features.
- A way to plug in specialized helpers for bills, contracts, financial docs, videos and HR tasks.
- A setup that fits naturally into my existing stack (Azure / Linux / Python).
That’s how Flooky-AI started: a Flask app that fronts Anthropic’s Claude API, adds light conversation memory, and exposes a few domain-specific helpers — without turning into a giant SaaS.
The target user is someone who wants a personal AI assistant they can audit, run,
and adapt. You configure it with a .env file, deploy it like any other Flask app,
and get a friendly UI that lives under flooky.space or your own domain.
2. Architecture & Project Layout
Flooky’s architecture is intentionally small and readable. Everything is centered around a simple Flask application with a “Claude service” wrapper and a set of modular processors.
2.1 High-Level Flow
At a high level, the flow looks like this:
- The browser sends a chat request (message + optional helper context).
- Flask receives it in
app.pyand decides which processor(s) to call. - Processors build prompts, extract key information, or summarize documents.
claude_service.pysends a request to Anthropic’s Claude API.conversation.pyprovides short-term memory across messages.- The JSON response is rendered back into the chat UI.
The directory structure in the repo looks like this:
Flooky-AI/
├─ static/ # CSS/JS, images, favicon, etc.
├─ templates/ # Jinja2 templates (chat, about, contact, donation)
├─ app.py # Flask app, routes, chat entrypoint
├─ claude_service.py # Anthropic API wrapper
├─ conversation.py # short-term conversation memory
├─ helpers.py # shared utilities & formatting
├─ bill_processor.py # "understand my bill" helper
├─ contract_processor.py # contract & clause analysis
├─ financial_processor.py # financial docs summary & metrics
├─ video_analyzer.py # video / URL analysis helper
├─ hr_helper.py # CV & cover letter prompts
├─ config.py # env var loading, defaults, safety
├─ .env.example # template for configuration
└─ requirements.txt # Python dependencies
For the frontend, Flooky sticks to vanilla HTML/CSS/JS inside
static/ and templates/. No heavy SPA framework — just enough JS to
handle chat requests, loading indicators, and small UI states.
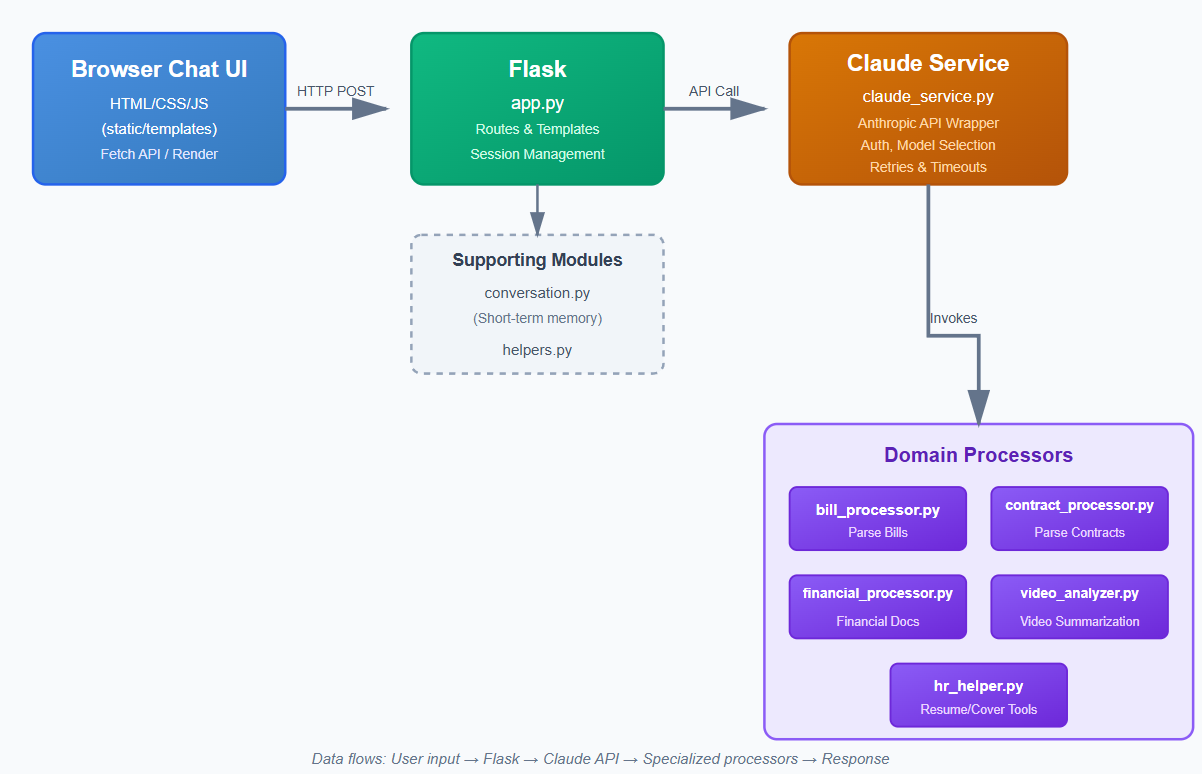
2.2 Modules and Their Responsibilities
Each Python module has a clear, single responsibility:
app.py— Flask app factory, routes, template rendering, and HTTP entrypoints.claude_service.py— low-level Anthropic client: headers, models, timeouts, retries.conversation.py— light, in-process memory for ongoing chat sessions.helpers.py— shared formatting, prompt utilities, and small helpers.bill_processor.py— specialized prompts and parsing for invoices/bills.contract_processor.py— contract sections, risk / clause summaries.financial_processor.py— P&L / balance sheet summarization, KPI extraction.video_analyzer.py— summarization and key points for video URLs or transcripts.hr_helper.py— CV and cover letter suggestions tailored to job descriptions.config.py— loads environment variables and sets safe defaults.
This separation means you can work on a specific helper (for example,
financial_processor.py) without touching the main app. It’s also friendly for
unit tests if you add them later.
3. Implementation – From Clone to First Conversation
Let’s walk through what it takes to run Flooky locally, wire it to Claude, and start talking.
3.1 Cloning the Repo & Installing Dependencies
First step: grab the repository and install the Python dependencies into a virtualenv or your environment of choice:
git clone https://github.com/ciscoAnass/Flooky-AI.git
cd Flooky-AI
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install -r requirements.txt
The requirements.txt includes Flask plus the Anthropic client and other utilities
used by the processors.
3.2 Configuring Environment Variables
Flooky uses a .env file for configuration. There is a checked-in
.env.example that shows all the keys you need without exposing secrets.
Typical variables include:
ANTHROPIC_API_KEY— your Claude API key.CLAUDE_MODEL— default model to use (e.g.claude-3-5-sonnet).FLASK_ENV—developmentorproduction.SECRET_KEY— Flask session key for cookies.- Any feature flags or debug toggles you decide to add in
config.py.
Setup is simply:
cp .env.example .env
# then edit .env with your keys and settings
The config.py module reads this file, applies defaults, and exposes configuration
to the rest of the app in a structured way.
3.3 Running Flooky in Development
In development you can use Flask’s built-in server or run it through Gunicorn locally:
export FLASK_APP=app.py
export FLASK_ENV=development
flask run # or: python app.pyOr, to mimic production a bit closer:
gunicorn --bind 0.0.0.0:8000 app:app
Once it’s running, visit http://localhost:8000 (or whatever port you chose) and
you’ll land on Flooky’s main chat screen with a friendly layout and a single prompt box.
3.4 Conversation Memory & Request Flow
When you send a message, the flow is:
- JavaScript in
static/js/captures the message and sends it viafetch()to a chat endpoint inapp.py. conversation.pyloads the recent history for your session (short-term memory).- If you clicked a special mode (bills, contracts, HR, etc.), the corresponding processor builds a targeted prompt using your input.
claude_service.pysends the final prompt + context to the Claude API.- The response is returned to the browser and rendered as a new message bubble.
Memory is intentionally “lightweight”: enough to keep context within a session, but not a full long-term knowledge base. That keeps the experience snappy and easier to reason about.
3.5 Specialized Helpers in Action
The real power of Flooky is in the processors. A few examples:
- Bills & invoices: you paste or upload text from a bill, and Flooky extracts totals, taxes, due dates, and highlights anything unusual.
- Contracts: feed in clauses and Flooky points out key terms, risks, and renewal/cancellation rules.
- Financial docs: summaries of P&L or reports, with KPIs in bullet-points.
- Video analysis: for a given video URL or transcript, Flooky produces a concise summary and key takeaways.
- HR helper: improve your CV, tailor a cover letter to a job description, or generate bullet points from your experience.
Internally, each processor builds prompts that are more structured than a raw “chat” style, pushing Claude to behave more like a focused assistant for that domain.
4. Security, Privacy & Operational Lessons
Because Flooky is meant to be privacy-friendly, a lot of design thought went into configuration, logging, and deployment choices.
4.1 Environment & Logging
- No secrets in the repo:
.envis git-ignored and only.env.exampleis committed. - Structured error responses: JSON errors with codes and human-readable messages, but without leaking stack traces in production.
- Logging is designed to be configurable: you can plug in JSON logs, request IDs and whatever pipeline you like (Elastic, Loki, etc.).
4.2 Security Checklist & Hardening Ideas
The README includes a security checklist that I treat as a living document. Highlights:
- Run behind HTTPS (reverse proxy like Nginx, Caddy or Azure Front Door).
- Set conservative timeouts and retries for external calls.
- Add CSRF protection where needed and tighten CORS.
- Sanitize any file uploads and validate file types.
- Rate-limit chat endpoints to avoid abuse.
4.3 Deployment on Azure Web App
Flooky is designed to be deployable almost anywhere, but I focused on Azure Web App as a first-class target. The deployment pattern is:
- Build a small Docker image or use the built-in Python runtime.
- Use the startup command:
pip install -r requirements.txt && pip install gunicorn && gunicorn --bind=0.0.0.0:8000 app:app. - Inject the environment variables via the Azure portal or Key Vault.
- Optionally, use the included Azure Pipelines YAML as a starting point for CI/CD.
From there you can tune scaling rules, monitoring and log ingestion like any other web app.
5. Roadmap – Making Flooky Smarter and Safer
Flooky already works as a daily driver AI assistant, but there’s a clear roadmap for future improvements.
- Streaming responses: use server-sent events (SSE) so answers stream into the chat instead of appearing all at once.
- Better observability: JSON logs, request IDs, and an optional
/metricsendpoint for Prometheus. - Redis-backed memory: move conversation memory from in-process to Redis so it survives restarts and scales horizontally.
- Fine-grained user accounts: per-user API keys, usage limits, and personal profiles for different AI “personalities”.
- More processors: think ticket analyzers, incident postmortem helpers, or Azure/DevOps configuration explainers.
The whole point is to keep Flooky modular and understandable: you can read the code in one evening, deploy it on your own infrastructure, and slowly grow it to match your workflows instead of adapting to yet another closed product.
💬 Want to discuss Flooky or extend it?
Reach out on LinkedIn or by email. I’m always happy to talk about building your own AI assistants, Anthropic’s Claude, Azure Web Apps, and privacy-friendly ways to integrate LLMs into real workflows.